



Frontend JavaScript frameworks – and more specifically for this post, React, – have always filled SEOs with fear about what search engines and their crawlers are able to crawl, execute, render and index. In this post we go over some basic SEO best practices for client-side JavaScript rendering and, more specifically, how to make React applications visible to Google and other search engines.
Note
Throughout this post we’ll be referencing three demo sites built internally with slightly different implementations (all use React). Links for these are below and the source code is also available to view on Github.
Example 1: React client side rendering: https://react-blog-site1.vercel.app/ - GitHub repo
Example 2: React & Next.js server side rendering: https://react-blog-site2.vercel.app/ - GitHub repo
Example 3: React & Next.js static site generation: https://react-blog-site3.vercel.app/ - GitHub repo
What is React?
React is a JavaScript framework for building user interfaces (the bits you interact with on a website – think buttons, toggles, notifications). It’s a modern framework making it comparatively easier to develop and manage projects.
It also has a large community of users behind it, meaning there’s a lot of functionality that can be imported into your project. For example, say you want confetti to rain down the screen when a user has created an account, you can import a specific “component” that another developer has created into your project (saving you from experiencing a huge headache).
React and JavaScript comparison
While the use of vanilla JavaScript (JavaScript without the use of a framework) and React are a means to the same end, JavaScript is an example of imperative programming – you write the steps to update the user interface – and React is an example of declarative programming (i.e. “I want to add a heading tag and I don’t care how it's done”).
When you compare JavaScript and React code for the same instruction – such as, add a H1 to the DOM (document object model) – you can see how much less code is required in React. Behind the scenes, React takes care of managing the DOM. In this instance, it creates an H1 element with some inner text and adds it to the DOM. In JavaScript we have to explicitly instruct this.
JavaScrip: 5 lines of code to add a H1
<script type="text/javascript"> const app = document.getElementById('app'); const header = document.createElement('h1'); const headerContent = document.createTextNode(‘Hello World',); header.appendChild(headerContent); app.appendChild(header);</script>
React: 2 lines of code to add a heading
<script type="text/jsx"> const app = document.getElementById("app") ReactDOM.render(<h1>Hello world</h1>, app)</script>
Types of rendering
Rendering is the process that turns code into a user interface (what we see when we view a webpage in a browser). It largely falls into three buckets:
- Client-side rendering
- Server-side rendering
- Static-site generation
Client side rendering
Client-side rendering is when the browser (the user's browser is the client) is responsible for rendering the page. The HTML and JavaScript is sent to the browser and the browser renders the JavaScript to create a webpage. This is how React and other frontend frameworks like Vue and Angular work.
Looking at our example application 1, if you examine the source code and compare that to the DOM (as seen in Chrome DevTools), you can see what has been rendered by the browser after the first HTML response. For example, React source code out of the box looks like this (no content!):
Source code

The source code shows no content, but the page in the browser renders as below. We now have content inside of the ‘root’ id which the browser has rendered.
Browser

Chrome DevTools: DOM
Server-side rendering
Server-side rendering is when a page request is created on the server and returns the HTML document. If you look in the source code and compare that to the DOM in Chrome DevTools, if the source code and the DOM are the same, the page is being rendered server side.
Looking at our example application 2, the source code is the same as the DOM (when viewed in Chrome DevTools):
Static site generation
Static-side generation, an increasingly more common practice, is where the page is created ahead of time. When the page is requested by a user, it returns an HTML file that has already been created. It's essentially locating a file that is sat in a directory ready to go, making it super speedy.
It's worth noting that in practice sites some sites will use a mixture of client side, server side rendering and even static site generation. For example, a blog post might be a static file as it is not going to change, but a filterable page might be a client or server side rendering as it needs to update as and when users toggle filters.
Dynamic rendering
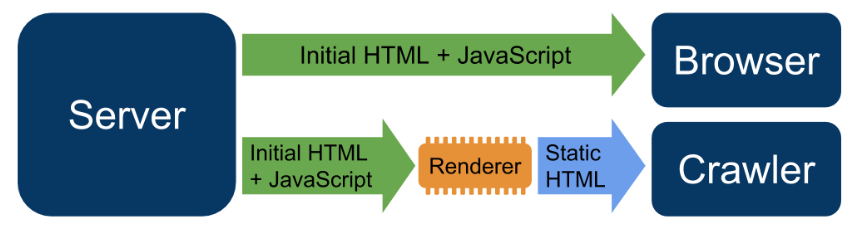
Another type of rendering is known as dynamic rendering. This is where a browser and a crawler receive different versions of the page.
While the browser receives the initial HTML and Javascript, which is then rendered by the browser to create the page, the pre-rendered HTML is served to the crawler, thereby showing the crawler and the browser the same content.
This means that Googlebot is able to see the page content without having to render the page (more on that shortly).
How does Googlebot crawl and index pages?
Google has web crawlers that crawl every and collect data from every page they can discover on the web, which is a mammoth and continuous task.
Due to the size of the internet and resources required, Googlebot makes a request and uses the initial HTML response to index a page (they do not render the JavaScript like a browser on the first request).
If they’re able to detect that the page is using client-side rendering or a lot of JavaScript, they will place the page in a queue and then attempt to crawl and render the page at a later date to try to understand the contents of the page.
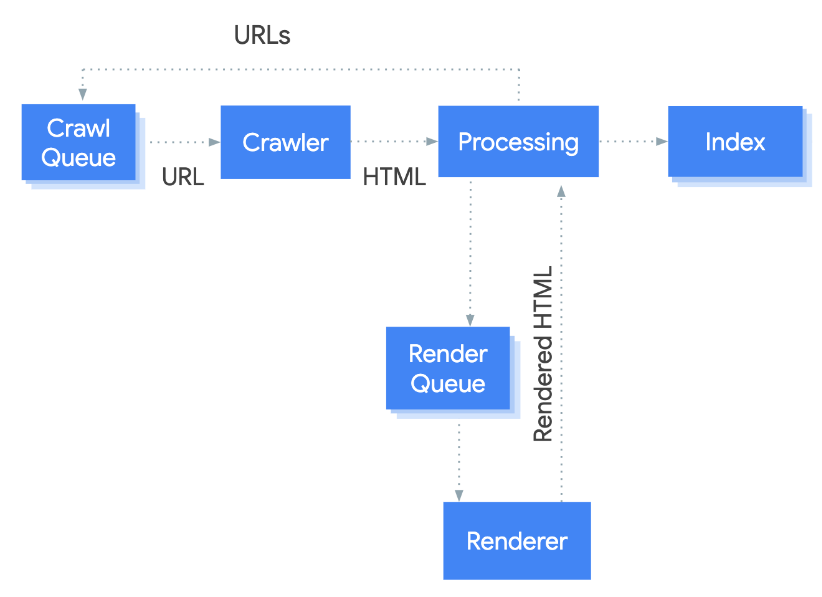
This could take hours, days or weeks depending on the priority that Google places on your domain. Additionally, note my use of the word attempt – search engines often have trouble “understanding” the contents of a page depending upon the JavaScript used.
While search engines have become much better at understanding JavaScript, certain JavaScript functionality is still not crawlable. For example, if the content is injected into the DOM after a button is clicked, Google will not see it. Googlebot and other search engine crawlers do not click buttons, submit forms, scroll down the page, hover on drop downs etc.
Can Google ‘understand’ React?
In regard to SEO, with a frontend framework like React, it all comes down to the following question: can Google ‘see’ the content on React applications?
The main concern is that Googlebot cannot render the page or content. And if it sees what it thinks is an empty web page with no content, then it’ll dismiss it (meaning no organic ranking or traffic).
Let's take a look at our example application 1. This uses React and a ‘react-router’ (a module which can be imported into a React project for routing) to add example pages on their own unique URLs.
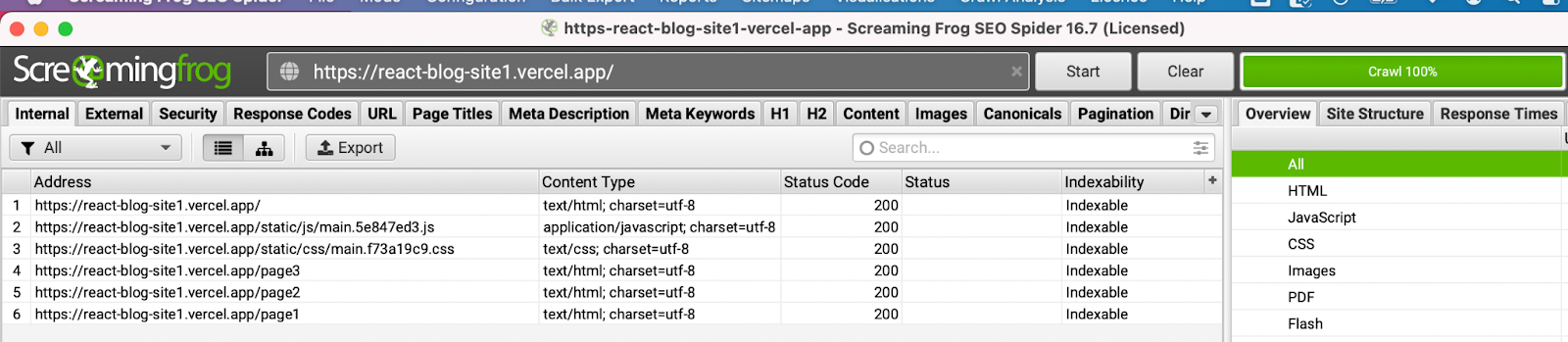
If we use a crawler (in this case Screaming Frog), and attempt to crawl our example application, we only find one document (as well as some CSS and JS files).
Additionally, Screaming Frog is unable to find any content on the page – so we have no pages and no content on this site if you look at the initial source code. And as explained earlier, this is Googlebot’s first port of call to crawl and index a web page.

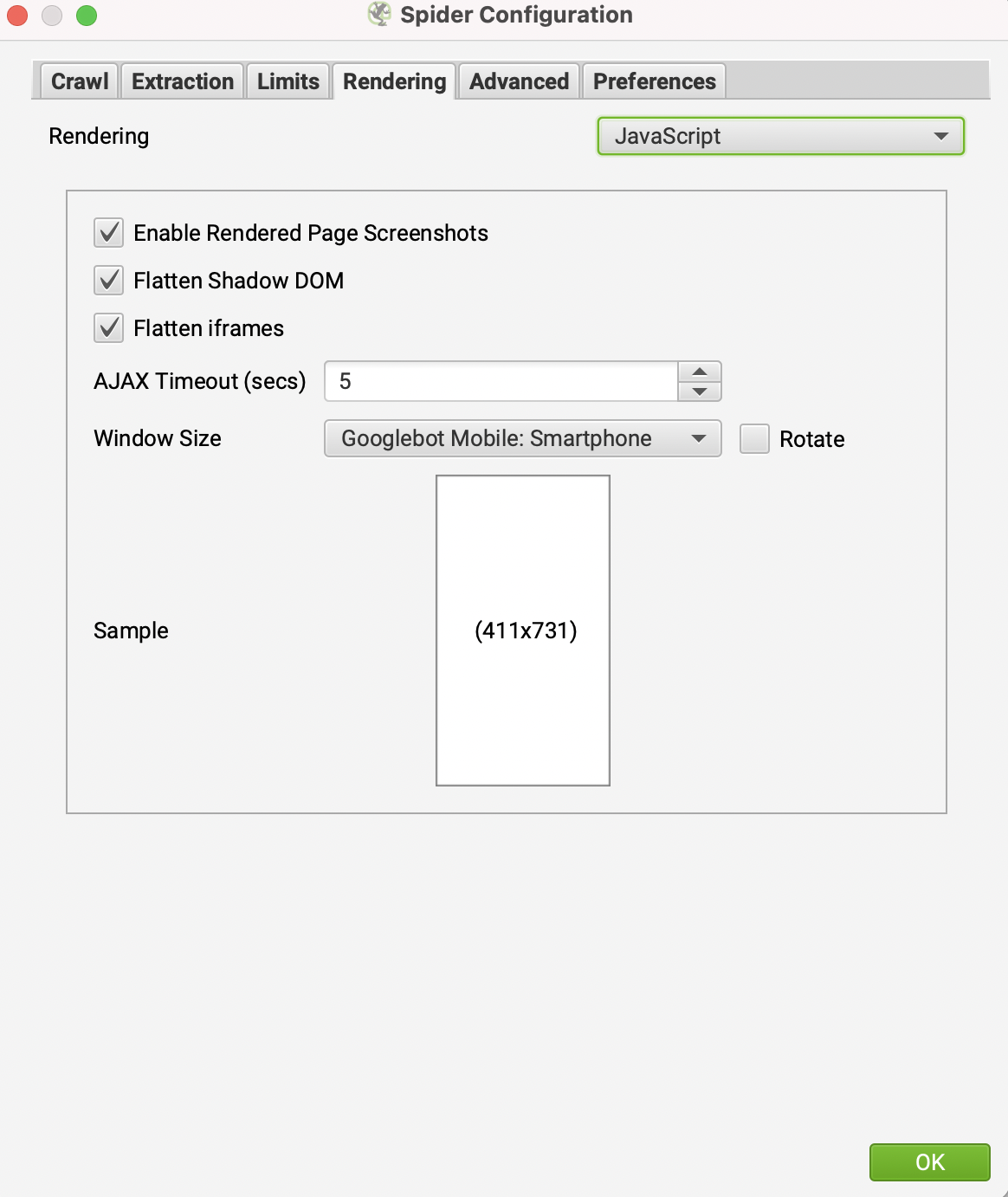
Googlebot's second port of call is to attempt to run the client side JavaScript and index the page based upon what it is able to render in the HTML. We can replicate this behavior by changing a setting in Screaming Frog so that our crawl executes the JavaScript and then extracts the contents of the page.
Within Screaming Frog go to ‘Configuration’ > ‘Spider’ > ‘Rendering’ and change the ‘Rendering’ from ‘text only’ to ‘JavaScript’.
With this setting changed, if we now crawl the site we can see that Screaming Frog has found all three of our pages as well as the page content.
Fetch and render with Google
Additionally, we can check how Google views our page by using the mobile friendly test or URL inspection tool within Google Search Console. These applications will attempt to execute JavaScript and show the rendered HTML.
Mobile friendly test
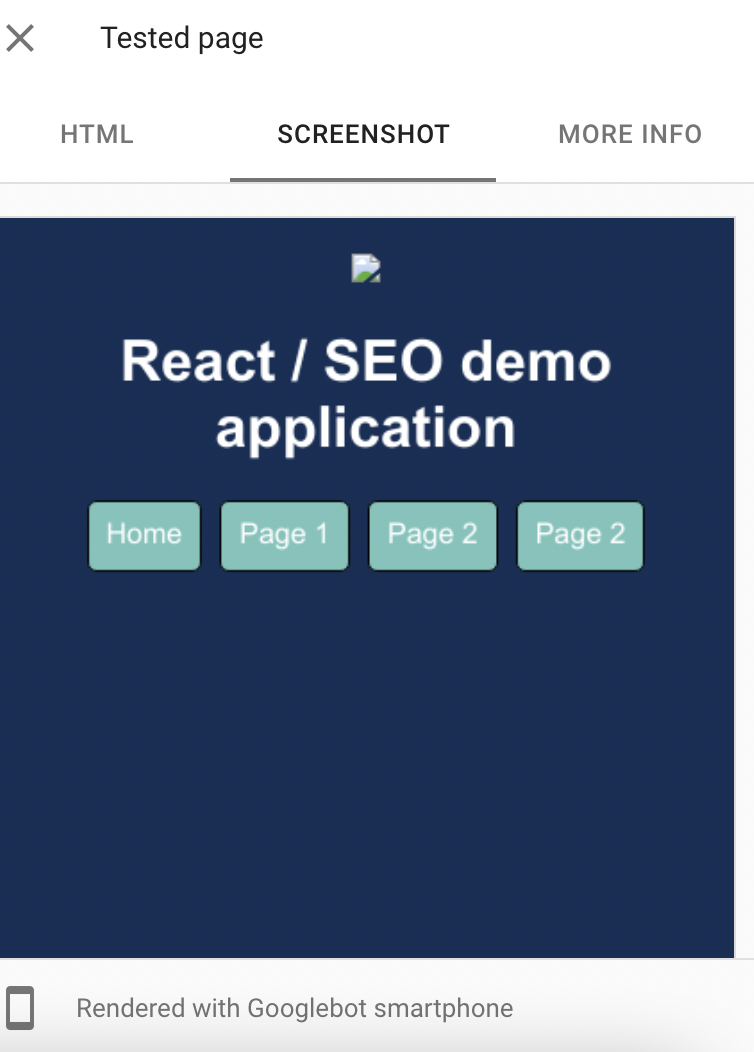
Google can render JavaScript and “see” content on React applications but only if it has been implemented correctly (see “React - need to know SEO implementations" below).
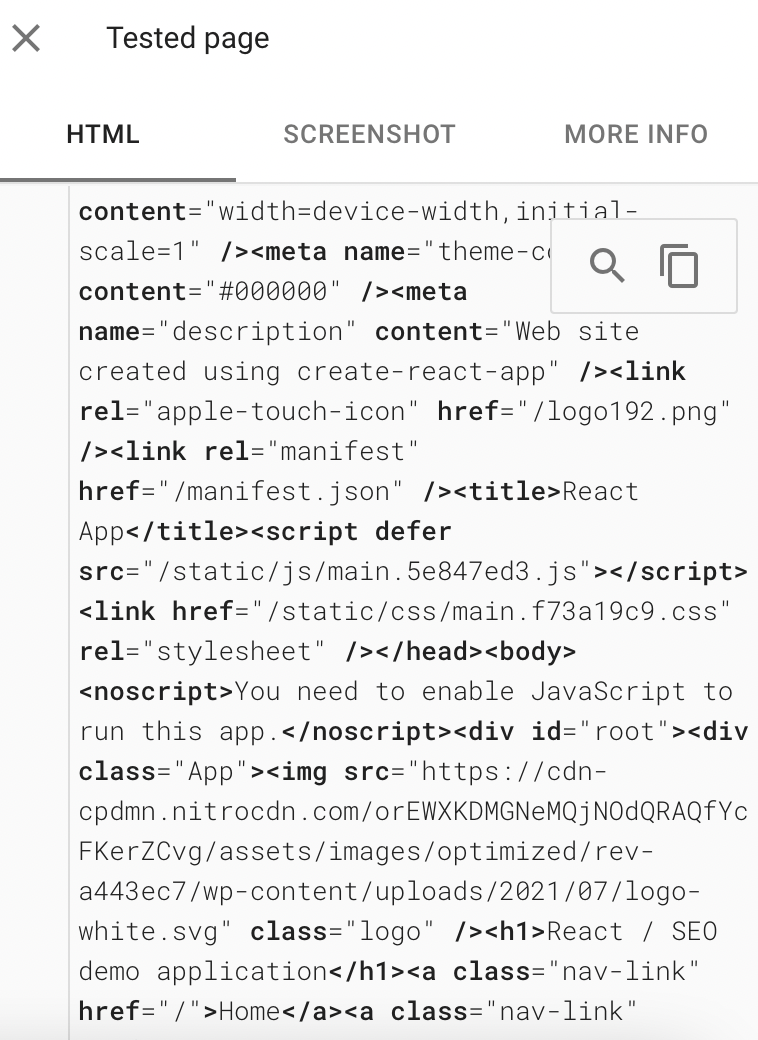
Based upon how this is rendered in Screaming Frog as well as Google's mobile friendly test, it's reasonably safe to say that our React site is accessible and indexable (although this implementation can be improved, which we will come onto later).
It’s worth noting that we are simply illustrating how to make our site visible to Google with React, although there are some very obvious SEO optimisations that we would deploy for a real world site (think titles, headings, etc).
React: Need-to-know SEO implementations
If you’re publishing a website using JavaScript and client side rendering, there are a few fundamental implementations to get right …
1. Avoid single-page applications (use URLs)
Google needs pages to index. Each page needs a unique URL and clear targeting and optimisation. Using a single page and updating the DOM with content will not work for SEO.
2. Use HTML anchor tags instead of ‘onclick’ events
Googlebot finds pages through links – it does not click buttons or other elements to navigate to new pages. The use of event handlers means your site can be hidden from Googlebot, although navigable for your users.
3. Avoid AJAXing content on events
Similar to point two, any content that is AJAXed onto the page from a user event –for example when a user scrolls, hovers on an element, types in a search box – will not be seen by Google.
Google will only see content that is rendered in the HTML. Some of this functionality can still be used in an SEO-friendly manner, such as infinite scroll, but it requires further consideration outside the remit of this post.
4. Avoid slow render times
When Googlebot assumes the page has been rendered (network activity has stopped), or it reaches the time threshold, it will take a snapshot of the rendered HTML. If the page takes a very long time to render there is a risk that not all the HTML will be rendered in time – meaning Googlebot may not see all the content.
Do note that this not only applies to React, but any client-side rendering with JavaScript, which includes other frameworks like Vue and Angular.
Improving our React implementation
Looking at our first example site 1, we are rendering all the content client side. While this particular implementation will be seen and indexed by Googlebot, best practice is typically to use server side rendering (we weigh up pros and cons of different implementations at the end of this article).
This ensures Googlebot and other search engines crawlers will see content and also avoid indexation delays (render queue).
Introducing Next.js
Next.js was created by Vercel and enables React-based applications to use server-side rendering and static site generation.
Server-side rendering
With some small changes to our initial application, we can use Next.js to add server-side rendering to our application (our second demo application here).
You’ll note that the site is a replica of the first example site – however, if you compare the source code and the DOM in Chrome DevTools, you’ll see no difference.
Source code

Chrome DevTools
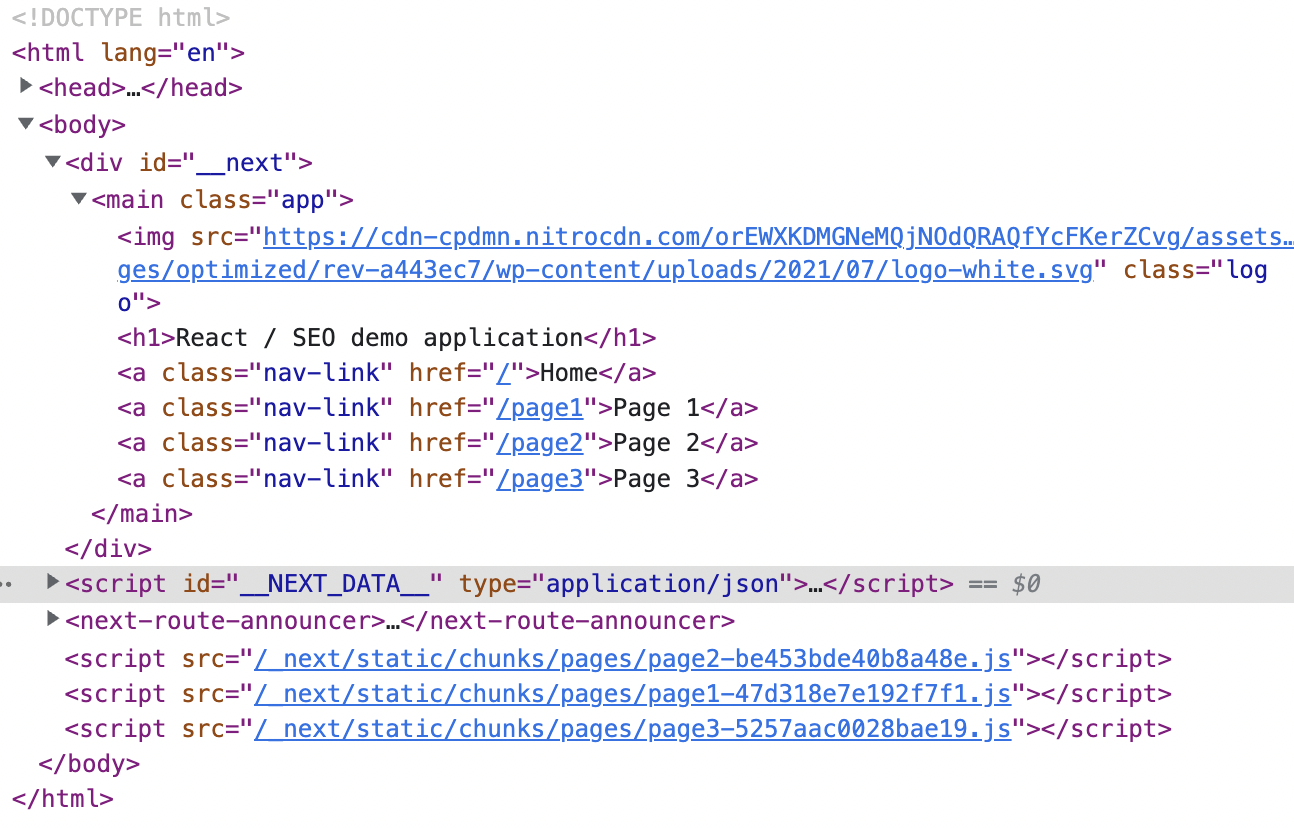
Furthermore, crawling the site (without rendering), we can see that all the pages and content is accessible within the source code.
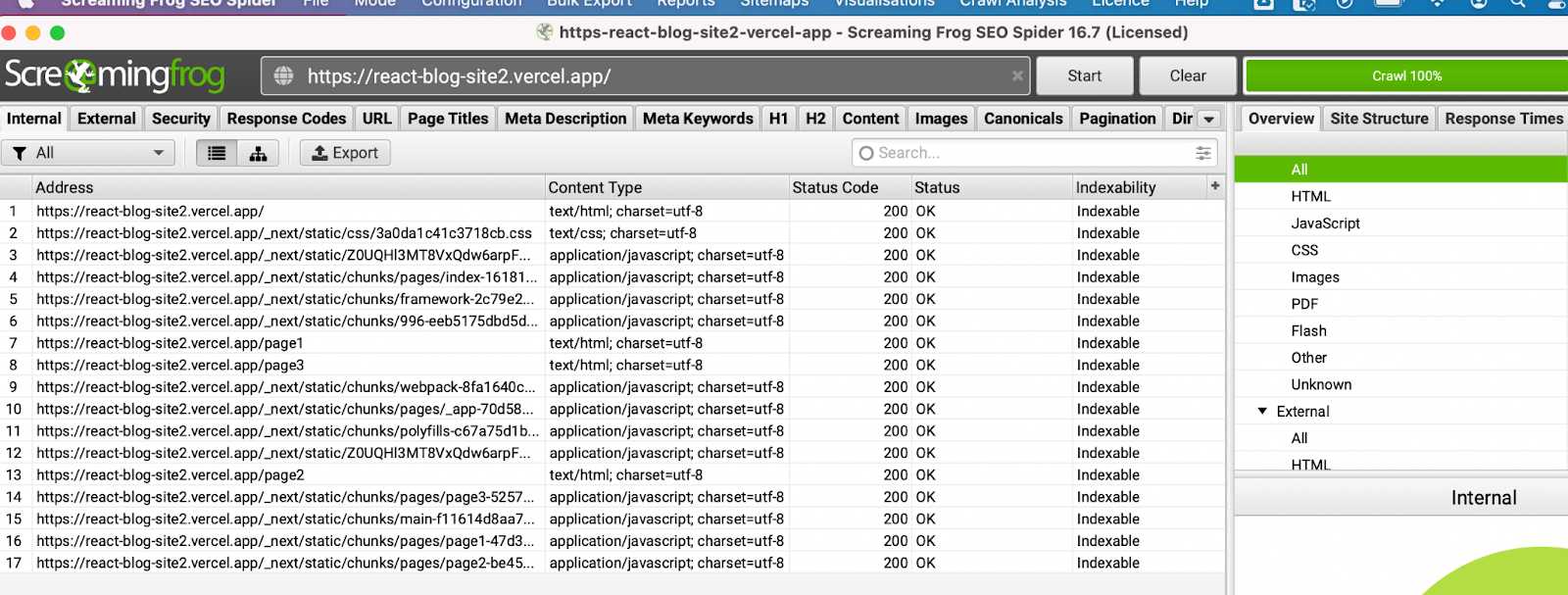
Static-site generation
Lastly, Next.js also allows static-site generation. By running a simple export command you generate all the HTML, CSS and JS for your site. This export converts all your React components into HTML which, similar to server-side rendering, means Googlebot can see all the content on the page within the initial page source without having to render JavaScript.
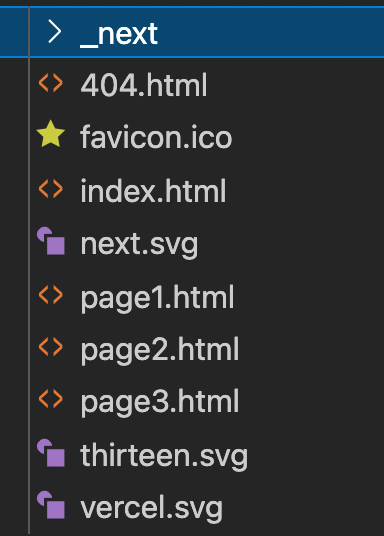
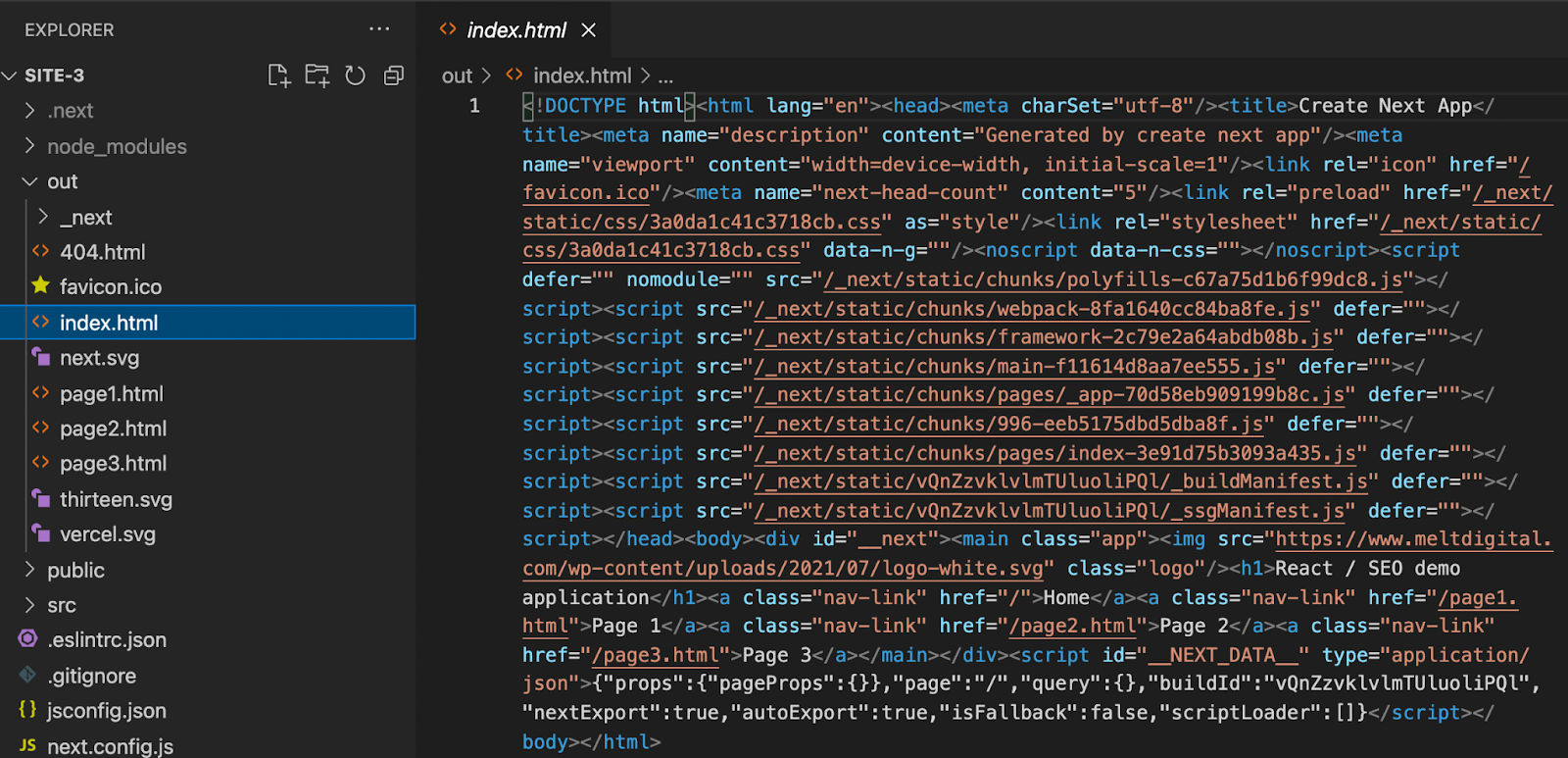
Looking within the index.html you can see all the page content. This is true for all the pages on this very limited site (page1.html, page2.html, page3.html).
Static sites are very fast and super secure. They are also serverless – if you create a true static site – as all the HTML has already been created, which means you don’t have to worry about managing a server.
They do, of course, have their downsides, such as lengthy rebuild times (think about what that means if you have tens or hundreds of thousands of pages), and limited functionality.
Which implementation to choose for SEO?
The simple answer is static site generation (prerendered and super fast), but in reality it's not so simple – the implementation comes down to the functionality required, resource and skill sets in the business. That said, here are a few things to consider:
Is content time sensitive or frequently updated?
Based on the time to crawl and index sites using client-side rendering, content that is time sensitive or requires a lot of crawling (e.g. a page that shows the weekly football results) should not rely on client-side rendering. If this is the case, and you want to use React, add Next.js and add server-side or static page generation to your tech stack.
Site speed
Static sites nearly always win for speed. If you can produce static pages, even for some sections of your site, it's worth considering to make your website quicker.
Functionality
With static sites you lose some functionality. For example, if you need an API, that won’t work with static HTML pages, as you need some server-side code. In these instances you could use Next.js with its server-side rendering (and possibly static generation for some sections of the site).
Already using React?
If you're looking to make your React application SEO friendly – and you don’t want to spend time and resources developing with Next.js – it's worth considering using a prerendering solution. These solutions effectively crawl and render your page, add it to a database, and then return the rendered HTML when Googlebot (or other bots) request your content.
Conclusion
Although the focus of this post has been on React, a lot of these SEO best practices and implementations cover a whole range of front end frameworks, such as Angular or Vue.
While the SEO best practices stay the same, the implementation changes with the framework and the programming language. For example, for Vue and another frontend JavaScript framework similar to React, there is an additional framework called Nuxt, which is very similar to Next. It enables different rendering methods (client-side, server-side or static generation) to name but one feature. We hope you’ve found this useful.
–
Have a question related to JavaScript and SEO? We do a lot of JavaScript auditing so we’d love to hear from you.






















